Google uses its FeedFetcher crawler to cache anything that is put inside =image(“link”) in the spreadsheet.
For instance:
If we put =image(“http://example.com/image.jpg”) in one of the cells of Google spreadsheet, Google will send the FeedFetcher crawler to grab the image and cache it to display.
However, one can append random request parameter to the filename and tell FeedFetcher to crawl the same file multiple times. Say, for instance a website hosts a 10 mb file.pdf then pasting a list in the spreadsheet will cause Google’s crawler to fetch the same file 1000 times.
=image("http://targetname/file.pdf?r=0")
=image("http://targetname/file.pdf?r=1")
=image("http://targetname/file.pdf?r=2")
=image("http://targetname/file.pdf?r=3")
...
=image("http://targetname/file.pdf?r=1000")
Appending random parameter, each link is treated as different thus Google crawls it multiple times causing a loss of outbound traffic for the website owner. So anyone using a browser and opening just a few tabs on his PC can send huge HTTP GET flood to a web server.
Here, the attacker does not need a huge bandwidth at all. Attacker requests Google to put the image link in the spreadsheet, Google fetches 10 MB data from the server but since it’s a PDF(non-image file), the attacker gets N/A from Google. This type of traffic flow clearly allows amplification and can be disaster.
Using just a single laptop with multiple tabs open and merely copy pasting multiple links to a 10 mb file, Google managed to crawl the same file at 700+ mbps. This 600-700 mbps crawling by Google continued for 30-45 min. at which point I shut down the server. If I do the math correctly, I think it’s about 240 GB of traffic in 45 min.
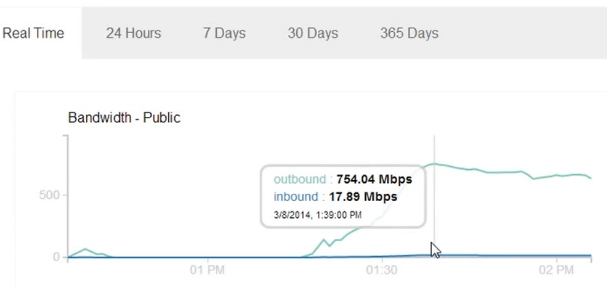
I was surprised that I was getting such high outbound traffic. With only a little bit of more load, I think the outbound will reach Gbps and the inbound traffic will reach 50-100 mbps. I can only imagine the numbers when multiple attackers get into this. Google uses multiple IP addresses to crawl and although one can block the FeedFetcher User Agent to avoid these attacks, the victim will have to edit the server config and in many cases it might be too late if this attack goes un-noticed. The attack could be so easily prolonged for hours just because of its ease of use.
After I found this bug, I started Googling for any such incidents, and I found two:
The Google Attack explains how the blogger attacked himself and got a huge traffic bill.
Another article, Using Spreadsheet as a DDoS Weapon explains similar attack but points that an attacker must first crawl the entire target website and keep the links in spreadsheet using multiple accounts and as such.
I found it a bit weird that nobody tried appending random request variables. Even though the target website has 1 file, adding random request variables thousands of request can be sent to that website. It’s a bit scary actually. Anyone copy pasting few links in the browser tabs should not be able to do this.
I submitted this bug to Google yesterday and got a response today that this is not a security vulnerability. This is a brute force denial of service and will not be included in the bug bounty.
May be they knew about this before hand and don’t really think it’s a bug ?
I hope they do fix this issue though. It’s simply annoying that anyone could manipulate Google crawlers to do this. A simple fix will be just crawling the links without the request parameters so that we don’t have to suffer.
A good fix will be to limit the rate with which you hit websites. One doesn’t need get 200OK responses to clog up a server. Someone can create a list of random paths like :
http://example.com/9awfj
http://example.com/oiwjef9
http://example.com/nbywk
which will all result in 404s from the server but still use up a lot of resources on the server. What is someone created a million of these.
Any crawling activity should be rate limited.
404 doesn’t take outgoing bandwidth. A prolonged attack on an actual file will use up many TBs of bandwidth and leave the website crippled with lots of bandwidth cost.
Some sites have custom 404 pages. I think WordPress does by default?
Either way, thanks for your well-researched article!
UPDATED: The attack can be blocked by using the User Agent which is the same for all FeedFetcher crawler. Thanks toast0 HN.
You’ve taken my concept from the Radware blog and took it one step further, to be even more devious, with a CDN cache busting variable. I knew it was just a matter of time before somebody made it worse. Thanks for attributing my original article.
Pour bloquer cette attaque, il possible d’utiliser le fichier htaccess