[Update]
Facebook Notes allows users to include <img> tags. Whenever a <img> tag is used, Facebook crawls the image from the external server and caches it. Facebook will only cache the image once however using random get parameters the cache can be by-passed and the feature can be abused to cause a huge HTTP GET flood.
Steps to re-create the bug as reported to Facebook Bug Bounty on March 03, 2014.
Step 1. Create a list of unique img tags as one tag is crawled only once
<img src=http://targetname/file?r=1></img>
<img src=http://targetname/file?r=1></img>
...
<img src=http://targetname/file?r=1000></img>
Step 2. Use m.facebook.com to create the notes. It silently truncates the notes to a fixed length.
Step 3. Create several notes from the same user or different user. Each note is now responsible for 1000+ http request.
Step 4. View all the notes at the same time. The target server is observed to have massive http get flood. Thousands of get request are sent to a single server in a couple of seconds. Total number of facebook servers accessing in parallel is 100+.
Initial Response: Bug was denied as they misinterpreted the bug would only cause a 404 request and is not capable of causing high impact.
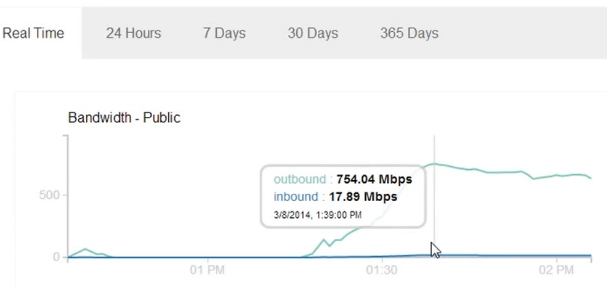
After exchanging few emails I was asked to prove if the impact would be high. I fired up a target VM on the cloud and using only browsers from three laptops I was able to achieve 400+ Mbps outbound traffic for 2-3 hours.
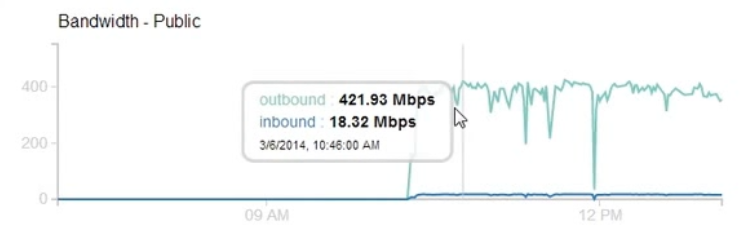
Number of Facebook Servers: 127
Of course, the impact could be more than 400 Mbps as I was only using browser for this test and was limited by the number of browser thread per domain that would fetch the images. I created a proof-of-concept script that could cause even greater impact and sent the script along with the graph to Facebook.
On April 11, I got a reply that said
Thank you for being patient and I apologize for the long delay here. This issue was discussed, bumped to another team, discussed some more, etc.
In the end, the conclusion is that there’s no real way to us fix this that would stop “attacks” against small consumer grade sites without also significantly degrading the overall functionality.
Unfortunately, so-called “won’t fix” items aren’t eligible under the bug bounty program, so there won’t be a reward for this issue. I want to acknowledge, however, both that I think your proposed attack is interesting/creative and that you clearly put a lot of work into researching and reporting the issue last month. That IS appreciated and we do hope that you’ll continue to submit any future security issues you find to the Facebook bug bounty program.
I’m not sure why they are not fixing this. Supporting dynamic links in image tags could be a problem and I’m not a big fan of it. I think a manual upload would satisfy the need of users if they want to have dynamically generated image on the notes.
I also see a couple of other problems with this type of abuse:
- A scenario of traffic amplification: when the image is replaced by a pdf or video of larger size, Facebook would crawl a huge file but the user gets nothing.
- Each Note supports 1000+ links and Facebook blocks a user after creating around 100 Notes in a short span. Since there is no captcha for note creation, all of this can be automated and an attacker could easily prepare hundreds of notes using multiple users until the time of attack when all of them is viewed at once.
Although a sustained 400 Mbps could be dangerous, I wanted to test this one last time to see if it can indeed have a larger impact.
Getting rid of the browser and using the poc script I was able to get ~900 Mbps outbound traffic.
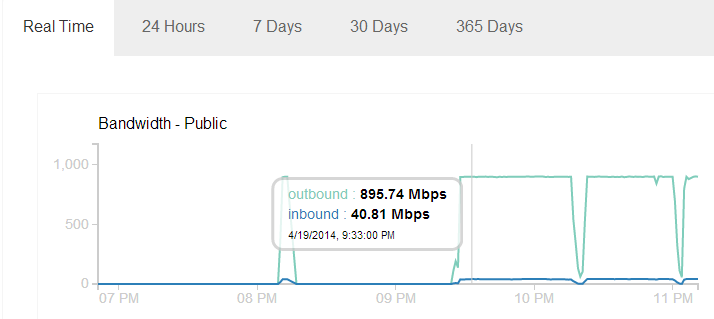
I was using an ordinary 13 MB PDF file which was fetched by Facebook 180,000+ times, number of Facebook servers involved was 112.
We can see the traffic graph is almost constant at 895 Mbps. This might be because of the maximum traffic imposed on my VM on the cloud which is using a shared Gbps ethernet port. It seems there is no restriction put on Facebook servers and with so many servers crawling at once we can only imagine how high this traffic can get.
After finding and reporting this issue, I found similar issues with Google which I blogged here. Combining Google and Facebook, it seems we can easily get multiple Gbps of GET Flood.
Facebook crawler shows itself as facebookexternalhit. Right now it seems there is no other choice than to block it in order to avoid this nuisance.
[Update1]
https://developers.facebook.com/docs/ApplicationSecurity/ mentions a way to get the list of IP addresses that belongs to Facebook crawler.
whois -h whois.radb.net — ‘-i origin AS32934′ | grep ^route
Blocking the IP addresses could be more effective than blocking the useragent.
I’ve been getting a lot of response on the blog and would like to thank the DOSarrest team for acknowledging the finding with an appreciation token.
[Update 2]
POC scripts and access log can now be accessed from Github. The script is very simple and is a mere rough draft. Please use them for research and analysis purposes only.
The access logs are the exact logs I used for ~900 Mbps test. In the access logs you will find 300,000+ requests from Facebook. Previously, I only counted the facebookexternalhit/1.1, it seems that for each img tag, there are two hits i.e. one from externalhit version 1.0 and one from 1.1. I also tried Google during the test and you will find around 700 requests from Google.