[Update]
Facebook Notes allows users to include <img> tags. Whenever a <img> tag is used, Facebook crawls the image from the external server and caches it. Facebook will only cache the image once however using random get parameters the cache can be by-passed and the feature can be abused to cause a huge HTTP GET flood.
Steps to re-create the bug as reported to Facebook Bug Bounty on March 03, 2014.
Step 1. Create a list of unique img tags as one tag is crawled only once
<img src=http://targetname/file?r=1></img>
<img src=http://targetname/file?r=1></img>
...
<img src=http://targetname/file?r=1000></img>
Step 2. Use m.facebook.com to create the notes. It silently truncates the notes to a fixed length.
Step 3. Create several notes from the same user or different user. Each note is now responsible for 1000+ http request.
Step 4. View all the notes at the same time. The target server is observed to have massive http get flood. Thousands of get request are sent to a single server in a couple of seconds. Total number of facebook servers accessing in parallel is 100+.
Initial Response: Bug was denied as they misinterpreted the bug would only cause a 404 request and is not capable of causing high impact.
After exchanging few emails I was asked to prove if the impact would be high. I fired up a target VM on the cloud and using only browsers from three laptops I was able to achieve 400+ Mbps outbound traffic for 2-3 hours.
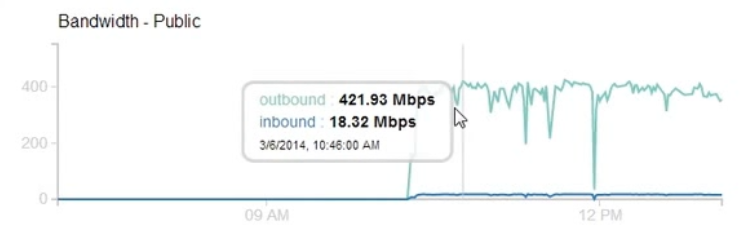
Number of Facebook Servers: 127
Of course, the impact could be more than 400 Mbps as I was only using browser for this test and was limited by the number of browser thread per domain that would fetch the images. I created a proof-of-concept script that could cause even greater impact and sent the script along with the graph to Facebook.
On April 11, I got a reply that said
Thank you for being patient and I apologize for the long delay here. This issue was discussed, bumped to another team, discussed some more, etc.
In the end, the conclusion is that there’s no real way to us fix this that would stop “attacks” against small consumer grade sites without also significantly degrading the overall functionality.
Unfortunately, so-called “won’t fix” items aren’t eligible under the bug bounty program, so there won’t be a reward for this issue. I want to acknowledge, however, both that I think your proposed attack is interesting/creative and that you clearly put a lot of work into researching and reporting the issue last month. That IS appreciated and we do hope that you’ll continue to submit any future security issues you find to the Facebook bug bounty program.
I’m not sure why they are not fixing this. Supporting dynamic links in image tags could be a problem and I’m not a big fan of it. I think a manual upload would satisfy the need of users if they want to have dynamically generated image on the notes.
I also see a couple of other problems with this type of abuse:
- A scenario of traffic amplification: when the image is replaced by a pdf or video of larger size, Facebook would crawl a huge file but the user gets nothing.
- Each Note supports 1000+ links and Facebook blocks a user after creating around 100 Notes in a short span. Since there is no captcha for note creation, all of this can be automated and an attacker could easily prepare hundreds of notes using multiple users until the time of attack when all of them is viewed at once.
Although a sustained 400 Mbps could be dangerous, I wanted to test this one last time to see if it can indeed have a larger impact.
Getting rid of the browser and using the poc script I was able to get ~900 Mbps outbound traffic.
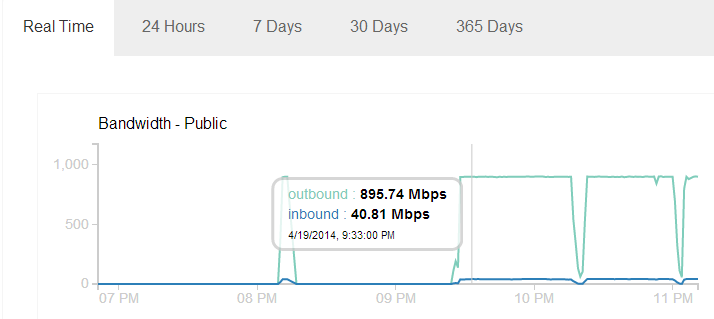
I was using an ordinary 13 MB PDF file which was fetched by Facebook 180,000+ times, number of Facebook servers involved was 112.
We can see the traffic graph is almost constant at 895 Mbps. This might be because of the maximum traffic imposed on my VM on the cloud which is using a shared Gbps ethernet port. It seems there is no restriction put on Facebook servers and with so many servers crawling at once we can only imagine how high this traffic can get.
After finding and reporting this issue, I found similar issues with Google which I blogged here. Combining Google and Facebook, it seems we can easily get multiple Gbps of GET Flood.
Facebook crawler shows itself as facebookexternalhit. Right now it seems there is no other choice than to block it in order to avoid this nuisance.
[Update1]
https://developers.facebook.com/docs/ApplicationSecurity/ mentions a way to get the list of IP addresses that belongs to Facebook crawler.
whois -h whois.radb.net — ‘-i origin AS32934′ | grep ^route
Blocking the IP addresses could be more effective than blocking the useragent.
I’ve been getting a lot of response on the blog and would like to thank the DOSarrest team for acknowledging the finding with an appreciation token.
[Update 2]
POC scripts and access log can now be accessed from Github. The script is very simple and is a mere rough draft. Please use them for research and analysis purposes only.
The access logs are the exact logs I used for ~900 Mbps test. In the access logs you will find 300,000+ requests from Facebook. Previously, I only counted the facebookexternalhit/1.1, it seems that for each img tag, there are two hits i.e. one from externalhit version 1.0 and one from 1.1. I also tried Google during the test and you will find around 700 requests from Google.
😛 great find mate and a very suitable title a bug in bug bounty program… wish you luck and lots of new vulnerabilities finding in near future.
I guess people will start to firewall off all the facebook servers, which is what Im about to do. Do you have a list of the attacking servers?
If I was you, I would be very tempted to make Facebook DDoS itself. If you trim the requests correctly and force the data center in, say, the US to make requests to Europe you could probably make them fill up their own bandwith back and forth using just a few servers.
I am not saying it would be a good idea, but the outcome would be extremely interesting.
It’s against the bug bounty rules to do this, hence one has to be careful here. I was only using browsers at first just because of that.
I thought about that, and had the same concern that Facebook might not scrape its own domain. However, if you own example.com, you might be able to point facebook-dos-test.example.com to one of facebook’s servers, and then point the image links to http://facebook-dos-test.example.com/user12345/giant-video-file.mp4
What if the note contained url to itself. Or a number of notes that formed a cycle. A “forkbomb” at FB?
Have you tried playing around with ftp:// requests instead of http:// requests? WhiteHat Security had a great talk about an ad network based DOS tool leveraging user’s browsers loading ads that I attended back in Aug: https://www.youtube.com/watch?v=ERJmkLxGRC0&index=9&list=PLiq_fDYFoqMocM7ADQCTfGAdI9CXA-kUs ; the slide at 11:38 shows what I’m potentially referring to.
I’m not sure if ftp works for Facebook, haven’t checked it. But if it is the number of requests, I used my own poc script where I can increase this number.
ftp:// will not work on Facebook and on every site that keeps PHP version up-to-date. Service from this calibre 100 % runs PHP in safe mode, with allow_url_fopen direcive setted to 0.
Facebook uses HHVM. Unless they’ve locked it down, the default for allow_url_fopen in HHVM is 1. http://docs.hhvm.com/manual/en/ini.list.php
This can be more destructive if you set image source to be a some search function in the victim site, for examaple http://www.example.com?q=random_param.
It will cause the remote site to do SQL queries itself for searching, and if the content that should be searched for matches is big, the result is
absolutely clear.
They should pay you and think how to fix it. Yeah, it’s complex and the way can be not fully effective, but will help a little bit. One way is to not allow more than N number images in one single note (i.e. GET requests limit), and if the limit is reached, the captcha can be shown to confirm that the viewer is human, so if the challenge is complete -> continue display the other pictures, if they are pictures 😀 (to avoid automatic DDoS attacks using this vulnerability).
Excuse my ignorance, as this isn’t my area of expertise. But is this exploit possible to run against Facebook itself? Linking images from Facebook servers and sending a multitude of get requests against itself? I would imagine that would motivate them to fix the problem.
Just my 2 cents. =)
Are they really that uncreative?
Go ahead and limit the request to three characters after the file dot or four for jpg or whatever. If that isn’t enough checksum the file to see if it’s already cached. Jesus Christ.
Although not widely used, dynamic images are valid so I suppose they don’t want to disable this feature. ETags is a creative solution but again the same checksums mapping to multiple URLs is also valid and would eventually show the incorrect image from time to time.
Or when receiving >N requests for a single URL (minus the query parameters) do a file checksum and then stop making requests for that file if 100% of those requests resulted in a file with the same checksum.
Whatever solution they end up going with, it doesn’t really matter.
What matters is what they are saying: “Giving a damn about the rest of the internet isn’t our job. Even when the solution is simple and saves us money, we don’t give a damn”.
I have been blocking facebookexternalhit due to the bad behaviour of this crawler for several years now and I have noticed no negative side effects so far.
Well this is something I didn’t expect to find, specially involving such a big problem with facebook.
I think it’s imposing a big threat for websites, specially with that kind of bandwith behind…
Thanks for sharing!
I actually now might login to Facebook to play with this. It would be very useful to generate load testing.
Try using CloudFlare for Anti-DDoS attacks, especially when you have Anti-Scraping feature on.
This is a great discovery and I’m a little surprised that FB wouldn’t pay you for the find. We at DOSarrest have already created a mini module to apply to a customer’s config in the event we run into this type of attack based on your findings, it saves us time and effort, rather than doing it on the fly. We appreciate your efforts on this and are willing to pay you $500.00USD for it. I’ll be in touch by email to work out the details.
Jwong
Good on ya Jenny for going out of your way!
Thank you for the appreciation.
I can’t believe they won’t fix this!, I don’t think it will be a too hard to add some preventive measures such as 1) limiting the amount of images per note, 2) checking the domain of each image (limit per domain), 3) verify that there are no repeated images by comparing checksums or similar… Anyway, great job!
Would one be able to mitigate this by blocking all these ranges with IPTables/PF
whois -h whois.radb.net — ‘-i origin AS32934’ | grep ^route
https://developers.facebook.com/docs/ApplicationSecurity/
One way is to block all the crawler IP. If the whois returns all the IP range used by Facebook crawlers, definitely we could block it to prevent the damage. We might have to verify if the command includes Facebook’s externalhit crawlers.
Maybe I’m misunderstanding the nature of the problem, but I don’t see why this is a Facebook problem. You can create an HTML file on your own PC with thousands of img tags with dynamic URLs to an image on the targeted server, open it in your own browser, and achieve the same result, no?
Most households don’t have a 400 Mbps internet connection, so that’s the catch. Even with the normal internet speed you can achieve this amplification using Facebook. If you don’t use Facebook for the crawl, you will be limited by your internet speed.
There is (or was) a similar issue with WhatsApp. Late 2011 / Early 2012 I broke the protocol and wrote a custom client.
WhatsApp allows you to send a image stanza which (on android and ios iirc) preloads the image from a given URL.
Now the spicy part about this is that you can spam and probably even broadcast (to the entire XMPP server! – so a couple hundred thousand users you don’t even know) these image stanzas due to various other bugs.
The idea behind this sort of ddos is that not the mobiles itself will preload the data but the network carrier might do this at the transmitting station/hotspot. A simple image stanza in a broadcast could therefore theoreticly cause million of distributed GET requests from mobile network hotspots accross the earth all at once.
Untested though and probably (hopefully) fixed by now.
hi bro .. what should i replace into /file?
iwill replace it some files on the site or what ?
Rate limiting anyone?
There’s a step I don’t understand:
Step 2. Use m.facebook.com to create the notes. It silently truncates the notes to a fixed length.
Care to expand on that? Great post anyway, I just blogged about it 🙂
It’s just a small technical detail while automatically creating notes. m.facebook.com does not validate on length of note and just truncates the note to a fixed size. So you can try to create a large note and it will just silently truncate to max length, makes it a bit easy as one does not have to calculate the note length accepted by Facebook.
alright! Got it
This is a great find, and as you say, something that wouldn’t be difficult for them to fix, so I’m surprised they’re not. If you wanted to ddos a target company, you’d just have to use google to find a large file they host, write your note pointing to that file, and take them out – essentially making Facebook ddos targets. Then they would have to take action. Nice work!
This means we can use Google to DDoS Facebook and Facebook to DDoS Google? Awesome!
This means both of them can be abused to have an even greater impact on an external website.
Would love to talk
Seems like the same thing we outlined here.
This is a lot of work to create a small amount of traffic compared to pretty much every modern method of DDoS, is easily blockable, is easily detectable. I wouldn’t bother fixing this either since it offers no improvement on an attack.
let just say 😀 i aslo found bugs on facebook but still got these kinds of replays
like
we can not fix the bug
or this bug was reported before 😀
which means they donot care
im sure there millions of bugs in facebook website
but they donot want to fix it
cause they will feel shame and they will lose money 😈 😆
but anyway great bug you found and you should get reworded sorry for my week English
This is a great find, i can’t believe they won’t fix it!
Leading BDoS vendor has a HTTP mitigation option that would automatically and dynamically block such requests (for HTTP and HTTPS) and protect the potential victim.
We reported your findings today here. Thank you
I tested it with 10 notes and 1000 random links, viewed bandwidth graph, nothing 🙂 only 1-2 mbit increased
If you are using 10 notes, make sure all 10×1000 links are unique. Take a bigger file to crawl and see what happens. If using a browser, may be you need more notes.
Just ran some tests of my own.
Facebook uses Akamai CDN service to process the images.
This probably explains why they refused to fix the issue – it is an external service.
Seems Akamai have fixed it anyway.
The CDN stops processing the images after the first few hundred and they refuse to load any more from that domain.
Last time I checked this was not fixed. I will run the tests soon to verify this.
This is definitely not fixed. I just created 1 note with 1200 links. Just used 1 tab to view the notes and the bandwidth is 300+ Mbps. I’m using a 13 Mb pdf file.
http://chr13.com/wp-content/uploads/2014/04/b1.png
Something isn’t right here.
Can you confirm that the image URLs are in the below format?:
https://fbexternal-a.akamaihd.net/safe_image.php?d=%5Burl-encoded image URL]
The final url is the safe_image.php on akamai.
Tried it with 500 unique links repeated over 15 notes. Didn’t notice much change.
Make sure you have 15×500 unique links. And visit them at once in 15 tabs. I’ll have to check if it has been already fixed or not.
Fun is, that all the files are downloaded in to RAM of all users. So every user will have over 1 GB new data in RAM. This may overload the memory on less powerful computers.
Wouldn’t briefly caching images on their server space itself be viable?
In the sense that for a brief period of time the ISP or whatever the Facebook server farm is running can redirect all those links to this cached copy and that will only be like serving the same image.
Pretty much like how it works on a regular computer where processes are cached (L1, L2, L3, L4) and when needed can be brought up immediately rather than having to get it from the Disk every single time. Facebook is doing that right getting it from the Disk every single time? In such a position, I find that this could help.
It is not a real problem of FB but in general how agent/proxy/pre-fetch agent handle static resource with querystring.
What you should do is nothing FB specific but redirect all requests with QueryString to URL without QueryString. (If you are not using this skill for http-cache-invalidation)
RewriteRule ^/static/(.+)?(.*) /static/$1
Then you saved your bandwidth.
For the number of request, you may set a limit or let them queue? move to nginx if you are still using old good apache
This *is* a Facebook problem. If they were not caching then I would say this is not a real problem. Then the attacker would have to create a legitimate traffic or simulate thousands of legitimate crawlers.
If Facebook wants to crawl it should crawl properly.
So, everyone on the internet should fix this ? This affects *everyone* on the internet, I somehow feel people miss that. Most third world countries don’t have so much bandwidth. It’s just less pain for the rest of the world if Facebook would fix this.
Very great post. I just stumbled upon your blog and wished to mention that I have
really loved surfing around your weblog posts.
In any case I will be subscribing for your feed and I’m hoping you write again very soon!
Hi chr13, I’d love to know how you figure out all the ajax post parameters (__a, __dyn, __req, etc). Could you give me a link or some info? I’d really appreciate it
Fiddler, Live HTTP headers
actually I’ve got something working now, just using the data from another POST. Seems kind of superfluous at the moment – I know they didn’t used to need these arguments at all. Guessing they’ll probably do more with them in the future…
Where can I find a FREE website to monitor the bandwidth around websites?
is this still working?
I’m trying to generate multiple and then paste them into a FB note.. I’m using this script:
window.onload = function(){
var JIM = document.getElementById(‘JIM’);
var DynamiCreate = function(){
var i = 0
var maxSize = 4000
while(i < maxSize){
i++;
JIM.innerText += "” + “\n”;
}
};
DynamiCreate();
}
It creates a list like this:
…
etc…
I’m doing right or wrong? Should it works?
*It creates a list like this:
etc….
Sorry for the precedent post, i forget to use
tagOmg it’s a bit diffucult post the code here, I’m sorry…
@chr13: please remove my last 2 posts,
however have a look to this code here: http://jsfiddle.net/9ZDYw/
It creates a list, then I copy it and paste into a FB note..
Should this work??
Good find on this, I talked about the potentials of this a while ago in my blog at http://blog.radware.com/security/2014/03/wordpress-ddos-and-other-http-reflectors/ Once somebody starts daisy chaining these together it will become a huge amplifier. On premise DDoS equipment is definitely a requirement and rate limiting is NOT going to fix it. Other sites are also very vulnerable to this kind of thing.